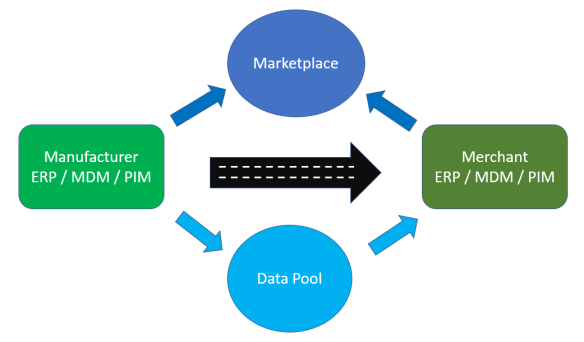
In the Select your solution service here on the site there are some questions about the scope of the intended MDM / PIM / DQM solutions and the number of master data entity records. These are among others:
- How many B2C customer (consumer, citizen) records are in scope for the solution?
- How many B2B customer / supplier (company) records are in scope for the solution?
- How many product (SKU) records are in scope for the solution?
When looking at what the needed disciplines, capabilities and eventually what solution is the best fit there are some stereotypes of organizations where we see the same requirements. Here are six such stereotypes:
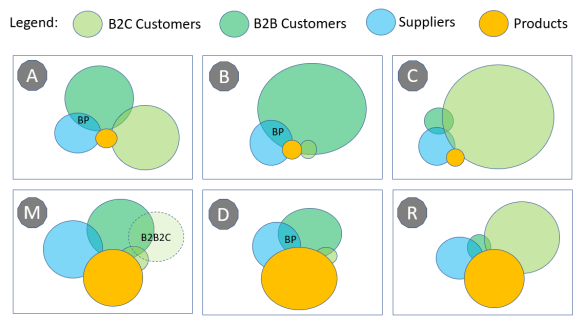
In type A, B and C party master data management is in focus, as the number of products (or services) is limited. This is common for example in the financial services, telco and utility sectors.
Type A is where we have both B2C customers and B2B customers. Besides B2B customers we also have suppliers and some company master data entities act both in customer and supplier roles or in other business partner (BP) roles.
Type B is where the business model is having B2B customers. One will though always find some anomalies where the customers are private, with selling to employees as one example.
Type C is where the business model is having B2C customers. One will though often find some examples of having a small portion of B2B customers as well. We find type C organizations in for example healthcare, membership and education.
In type M, D and R product master data management is of equal or more importance as party master data management is. At these stereotypes, we therefore also see the need for Product Information Management (PIM).
Type M is found at manufacturers including within pharmaceuticals. Here the number of products, customers and suppliers are in the same level. Customers are typically B2B, but we see an increasing tendency of selling directly to consumers through webshops or marketplaces. Additionally, such organizations are embarking in caring about, and keeping track of, the end costumers as in B2B2C.
Type D is merchants being B2B dealers and distributors (wholesale). Though it is still common to separate customer roles and supplier roles, we see an increasing adoption of the business partner (BP) concept, as there can be a substantial overlap of customer and supplier roles. In addition, suppliers can have fictitious customer (accounts receivable) roles for example when receiving bonusses from suppliers.
Type R is merchants being retailers. With the rise of ecommerce, retailers have the opportunity of, within the regulations in place, keeping track of the B2C customers besides what traditionally have been done in loyalty programs and more.
All master data domains, also those besides parties and products, matters in some degree to all organizations. The stereotypes guide where to begin and solution providers have the opportunity of doing well with the first domain and, if covered, proceed with the engagement when other domains come into play.