As examined in the post The Intersection Between MDM, PIM and ESG, environmental data management is becoming an important aspect of the offerings provided in solutions for Master Data Management (MDM) and Product Information Management (PIM). Consequentially, this will also apply to the Data Quality Management (DQM) capabilities that are either offered as part of these solutions or as standalone solutions for data quality.
This site has an interactive Select Your Solution service for potential buyers of MDM / PIM / DQM solutions. The service has a questionnaire and an undelaying model for creating a longlist, shortlist or direct PoC suggestion for the best candidate(s) according to the context, scope, and requirements of an intended solution.
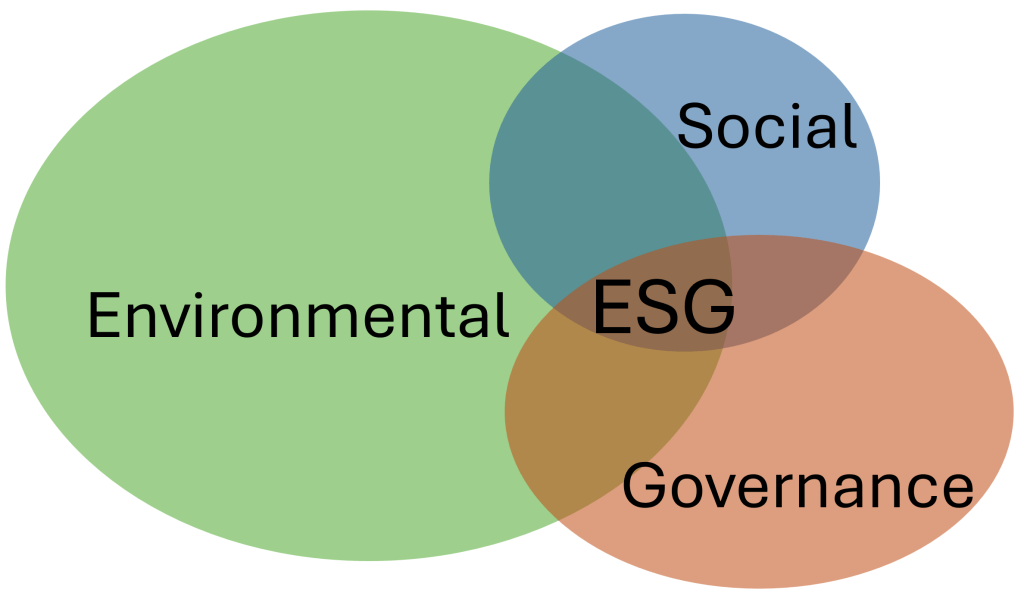
In line with the rise of the Environmental, Social and Governance (ESG) theme, the questionnaire and the underlying selection model must in the first place be enhanced with environmental data management aspects, as the environmental part of ESG is the one with the currently most frequently and comprehensive experienced data management challenges.
There is already established a good basis for this.
However, if you as either one from a solution end user organization with environmental data management challenges or a solution provider have input to environmental data management aspects to be covered, you are more than welcome to make a comment here on the blog or use the below contact form:
Today’s guest blog post is from Marcin Chudeusz of DIGNA.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms.
Have you ever experienced the frustration of missing crucial pieces in your data puzzle? The feeling of the weight of responsibility on your shoulders when data issues suddenly arise and the entire organization looks to you to save the day? It can be overwhelming, especially when the damage has already been done. In the constantly evolving world of data management, where data warehouses, data lakes, and data lakehouses form the backbone of organizational decision-making, maintaining high-quality data is crucial. Although the challenges of managing data quality in these environments are many, the solutions, while not always straightforward, are within reach.
Data warehouses, data lakes, and lakehouses each encounter their own unique data quality challenges. These challenges range from integrating data from various sources, ensuring consistency, and managing outdated or irrelevant data, to handling the massive volume and variety of unstructured data in data lakes, which makes standardizing, cleaning, and organizing data a daunting task.
Today, I would like to introduce you to Digna, your AI-powered guardian for data quality that’s about to revolutionize the game! Get ready for a journey into the world of modern data management, where every twist and turn holds the promise of seamless insights and transformative efficiency.
Digna: A New Dawn in Data Quality Management
Picture this: you’re at the helm of a data-driven organization, where every byte of data can pivot your business strategy, fuel your growth, and steer you away from potential pitfalls. Now, imagine a tool that understands your data and respects its complexity and nuances. That’s Digna for you – your AI-powered guardian for data quality.
Goodbye to Manually Defining Technical Data Quality Rules
Gone are the days when defining technical data quality rules was a laborious, manual process. You can forget the hassle of manually setting thresholds for data quality metrics. Digna’s AI algorithm does it for you, defining acceptable ranges and adapting as your data evolves. Digna’s AI learns your data, understands it, and sets the rules for you. It’s like having a data scientist in your pocket, always working, always analyzing.
Figure 1: Learn how Digna’s AI algorithm defines acceptable ranges for data quality metrics like missing values. Here, the ideal count of missing values should be between 242 and 483, and how do you manually define technical rules for that?
Seamless Integration and Real-time Monitoring
Imagine logging into your data quality tool and being greeted with a comprehensive overview of your week’s data quality. Instant insights, anomalies flagged, and trends highlighted – all at your fingertips. Digna doesn’t just flag issues; it helps you understand them. Drill down into specific days, examine anomalies, and understand the impact on your datasets.
Whether you’re dealing with data warehouses, data lakes, or lakehouses, Digna slips in like a missing puzzle piece. It connects effortlessly to your preferred database, offering a suite of features that make data quality management a breeze. Digna’s integration with your current data infrastructure is seamless. Choose your data tables, set up data retrieval, and you’re good to go.
Figure 2: Connect seamlessly to your preferred database. Select specific tables from your database for detailed analysis by Digna.
Navigate Through Time and Visualize Data Discrepancies
With Digna, the journey through your data’s past is as simple as a click. Understand how your data has evolved, identify patterns, and make informed decisions with ease. Digna’s charts are not just visually appealing; they’re insightful. They show you exactly where your data deviated from expectations, helping you pinpoint issues accurately.
With Digna, every column in your data table gets attention. Switch between columns, unravel anomalies, and gain a holistic view of your data’s health. It doesn’t just monitor data values; it keeps an eye on the number of records, offering comprehensive analysis and deep insights with minimal configuration. Digna’s user-friendly interface ensures that you’re not bogged down by complex setups.
Figure 3: Observe how Digna tracks not just data values but also the number of records for comprehensive analysis. Transition seamlessly to Dataset Checks and witness Digna’s learning capabilities in recognizing patterns.
Real-time Personalized Alert Preferences
Digna’s alerts are intuitive and immediate, ensuring you’re always in the loop. These alerts are easy to understand and come in different colors to indicate the quality of the data. You can customize your alert preferences to match your needs, ensuring that you never miss important updates. With this simple yet effective system, you can quickly assess the health of your data and stay ahead of any potential issues. This way, you can avoid real-life impacts of data challenges.
Whether you prefer inspecting your data directly from the dashboard or integrating it into your workflow, I invite you to commence your data quality journey. It’s more than an inspection; it’s an exploration—an adventure into the heart of your data with a suite of features that considers your data privacy, security, scalability, and flexibility.
Automated Machine Learning
Digna leverages advanced machine learning algorithms to automatically identify and correct anomalies, trends, and patterns in data. This level of automation means that Digna can efficiently process large volumes of data without human intervention, erasing errors and increasing the speed of data analysis.
The system’s ability to detect subtle and complex patterns goes beyond traditional data analysis methods. It can uncover insights that would typically be missed, thus providing a more comprehensive understanding of the data.
This feature is particularly useful for organizations dealing with dynamic and evolving data sets, where new trends and patterns can emerge rapidly.
Domain Agnostic
Digna’s domain-agnostic approach means it is versatile and adaptable across various industries, such as finance, healthcare, and telcos. This versatility is essential for organizations that operate in multiple domains or those that deal with diverse data types.
The platform is designed to understand and integrate the unique characteristics and nuances of different industry data, ensuring that the analysis is relevant and accurate for each specific domain.
This adaptability is crucial for maintaining accuracy and relevance in data analysis, especially in industries with unique data structures or regulatory requirements.
Data Privacy
In today’s world, where data privacy is paramount, Digna places a strong emphasis on ensuring that data quality initiatives are compliant with the latest data protection regulations.
The platform uses state-of-the-art security measures to safeguard sensitive information, ensuring that data is handled responsibly and ethically.
Digna’s commitment to data privacy means that organizations can trust the platform to manage their data without compromising on compliance or risking data breaches.
Built to Scale
Digna is designed to be scalable, accommodating the evolving needs of businesses ranging from startups to large enterprises. This scalability ensures that as a company grows and its data infrastructure becomes more complex, Digna can continue to provide effective data quality management.
The platform’s ability to scale helps organizations maintain sustainable and reliable data practices throughout their growth, avoiding the need for frequent system changes or upgrades.
Scalability is crucial for long-term data management strategies, especially for organizations that anticipate rapid growth or significant changes in their data needs.
Real-time Radar
With Digna’s real-time monitoring capabilities, data issues are identified and addressed immediately. This prompt response prevents minor issues from escalating into major problems, thus maintaining the integrity of the decision-making process.
Real-time monitoring is particularly beneficial in fast-paced environments where data-driven decisions need to be made quickly and accurately.
This feature ensures that organizations always have the most current and accurate data at their disposal, enabling them to make informed decisions swiftly.
Choose Your Installation
Digna offers flexible deployment options, allowing organizations to choose between cloud-based or on-premises installations. This flexibility is key for organizations with specific needs or constraints related to data security and IT infrastructure.
Cloud deployment can offer benefits like reduced IT overhead, scalability, and accessibility, while on-premises installation can provide enhanced control and security for sensitive data.
This choice enables organizations to align their data quality initiatives with their broader IT and security strategies, ensuring a seamless integration into their existing systems.
Conclusion
Addressing data quality challenges in data warehouses, lakes, and lakehouses requires a multifaceted approach. It involves the integration of cutting-edge technology like AI-powered tools, robust data governance, regular audits, and a culture that values data quality.
Digna is not just a solution; it’s a revolution in data quality management. It’s an intelligent, intuitive, and indispensable tool that turns data challenges into opportunities.
I’m not just proud of what we’ve created at DIGNA.AI; I’m most excited about the potential it holds for businesses worldwide. Join us on this journey, schedule a call with us, and let Digna transform your data into a reliable asset that drives growth and efficiency.
Cheers to modern data quality at scale with Digna!
This article was written by Marcin Chudeusz, CEO and Co-Founder of DIGNA.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms. Our first product, Digna offers cutting-edge solutions through the power of AI to modern data quality issues.
Contact me to discover how Digna can revolutionize your approach to data quality and kickstart your journey to data excellence.
Today’s guest blog post is from Marcin Chudeusz of DIGNA.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms.
Data quality isn’t just a technical issue; it’s a journey full of challenges that can affect not only the operational efficiency of an organization but also its morale. As an experienced data warehouse consultant, my journey through the data landscape has been marked with groundbreaking achievements and formidable challenges. The latter, particularly in the realm of data quality in some of the most data-intensive industries: banks, and telcos, have given me profound insights into the intricacies of data management. My story isn’t unique in data analytics, but it highlights the evolution necessary for businesses to thrive in the modern data environment.
Let me share with you a part of my story that has shaped my perspective on the importance of robust data quality solutions.
The Daily Battles with Data Quality
In the intricate data environments of banks and telcos, where I spent much of my professional life, data quality issues were not just frequent; they were the norm.
The Never-Ending Cycle of Reloads
Each morning would start with the hope that our overnight data loads had gone smoothly, only to find that yet again, data discrepancies necessitated numerous reloads, consuming precious time and resources. Reloads were not just a technical nuisance; they were symptomatic of deeper data quality issues that needed immediate attention.
Delayed Reports and Dwindling Trust in Data
Nothing diminishes trust in a data team like the infamous phrase “The report will be delayed due to data quality issues.” Stakeholders don’t necessarily understand the intricacies of what goes wrong—they just see repeated failures. With every delay, the IT team’s credibility took a hit.
Team Conflicts: Whose Mistake Is It Anyway?
Data issues often sparked conflicts within teams. The blame game became a routine. Was it the fault of the data engineers, the analysts, or an external data source? This endless search for a scapegoat created a toxic atmosphere that hampered productivity and satisfaction.
Data quality issues aren’t just a technical problem; they’re a people problem. The complexity of these problems meant long hours, tedious work, and a general sense of frustration pervading the team. The frustration and difficulty in resolving these issues created a bad atmosphere and made the job thankless and annoying.
Decisions Built on Quicksand
Imagine making decisions that could influence millions in revenue based on faulty reports. We found ourselves in this precarious position more often than I care to admit. Discovering data issues late meant that critical business decisions were sometimes made on unstable foundations.
High Turnover: A Symptom of Data Discontent
The relentless cycle of addressing data quality issues began to wear down even the most dedicated team members. The job was not satisfying, leading to high turnover rates. It wasn’t just about losing employees; it was about losing institutional knowledge, which often exacerbated the very issues we were trying to solve.
The Domino Effect of Data Inaccuracies
Metrics are the lifeblood of decision-making, and in the banking and telecom sectors, year-to-month and year-to-date metrics are crucial. A single day’s worth of bad data could trigger a domino effect, necessitating recalculations that spanned back days, sometimes weeks. This was not just time-consuming—it was a drain on resources amongst other consequences of poor data quality.
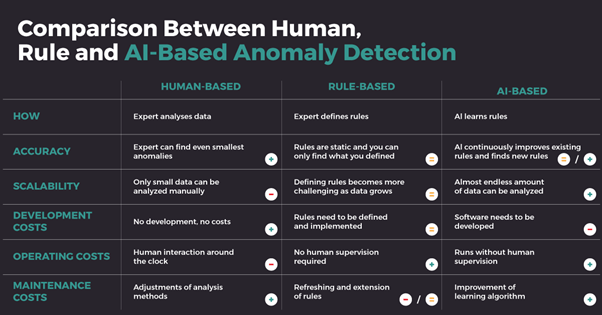
The Manual Approach to Data Quality Validation Rules
As an experienced data warehouse consultant, I initially tried to address these issues through the manual definition of validation rules. We believed that creating a comprehensive set of rules to validate data at every stage of the data pipeline would be the solution. However, this approach proved to be unsustainable and ineffective in the long run.
The problem with manual rule definition was its inherent inflexibility and inability to adapt to the constantly evolving data landscape. It was a static solution in a dynamic world. As new data sources, data transformations, and data requirements emerged, our manual rules were always a step behind, and keeping the rules up-to-date and relevant became an arduous and never-ending task.
Moreover, as the volume of data grew, manually defined rules could not keep pace with the sheer amount of data being processed. This often resulted in false positives and negatives, requiring extensive human intervention to sort out the issues. The cost and time involved in maintaining and refining these rules soon became untenable.
Comparison between Human, Rule, and AI-based Anomaly Detection
Embracing Automation: The Path Forward
This realization was the catalyst for the foundation of digna.ai. Danijel (Co-founder at Digna.ai) and I combined our AI and IT Know-How to create AI-powered software for Data Warehouses. This led to our first product Digna, we needed intelligent, automated systems that could adapt, learn, and preemptively address data quality issues before they escalated. By employing machine learning and automation, we could move from reactive to proactive, from guesswork to precision.
Automated data quality tools don’t just catch errors—they anticipate them. They adapt to the ever-changing data landscape, ensuring that the data warehouse is not just a repository of information, but a dependable asset for the organization.
Today, we’re pioneering the automation of data quality to help businesses navigate the data quality landscape with confidence. We’re not just solving technical issues; we’re transforming organizational cultures. No more blame games, no more relentless cycles of reloads—just clean, reliable data that businesses can trust.
In the end, navigating the data quality landscape isn’t just about overcoming technical challenges; it’s about setting the foundation for a more insightful, efficient, and harmonious future. This is the lesson my journey has taught me, and it is the mission that drives us forward at digna.ai.
This article was written by Marcin Chudeusz, CEO and Co-Founder of DIGNA.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms. Our first product, Digna offers cutting-edge solutions through the power of AI to modern data quality issues.
Contact us to discover how Digna can revolutionize your approach to data quality and kickstart your journey to data excellence.
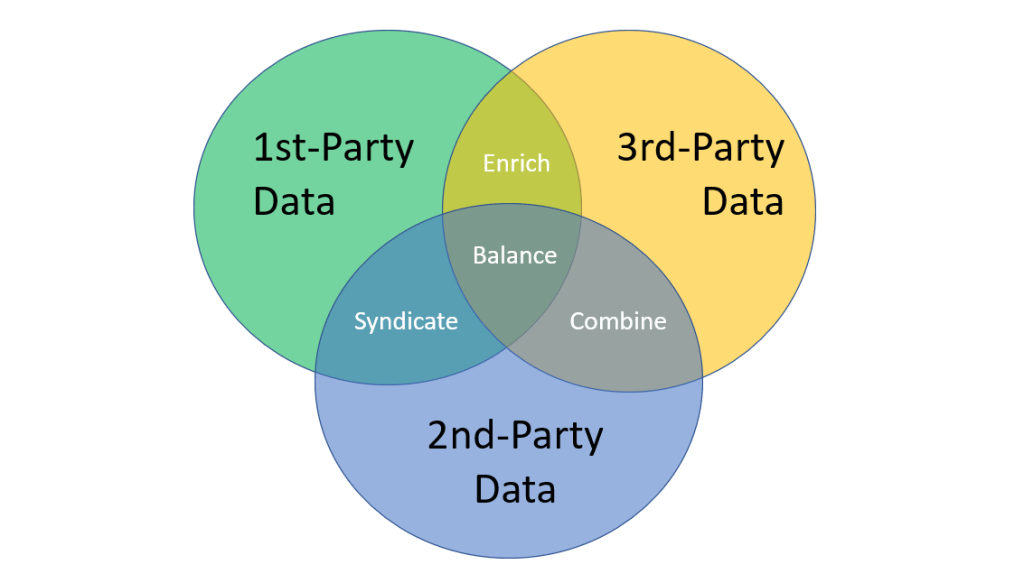
When working with Data Quality Management (DQM) within Master Data Management (MDM) there are three kinds of data to consider:
1st-party data is the data that is born and managed internally within the enterprise. This data has traditionally been in focus of data quality methodologies and tools with the aim of ensuring that data is fit for the purpose of use and correctly reflects the real-world entity that the data is describing.
3rd-party data is data sourced from external providers who offers a set of data that can be utilized by many enterprises. Examples a location directories, business directories as the Dun & Bradtstreet Worldbase and public national directories and product data pools as for example the Global Data Synchronization Network (GDSN).
Enriching 1st-party data with 3rd-party is a mean to ensure namely better data completeness, better data consistency, and better data uniqueness.
2nd-party data is data sourced directly from a business partner. Examples are supplier self-registration, customer self-registration and inbound product data syndication. Exchange of this data is also called interenterprise data sharing.
The advantage of using 2nd-party in a data quality perspective is that you are closer to the source, which all things equal will mean that data better and more accurately reflects the real-world entity that the data is describing.
In addition to that, you will also, compared to 3rd-party data, have the opportunity to operate with data that exactly fits your operating model and make you unique compared to your competitors.
Finally, 2nd-party data obtained through interenterprise data sharing, will reduce the costs of capturing data compared to 1st-party data, where else the ever-increasing demand for more elaborate high-quality data in the age of digital transformation will overwhelm your organization.
The Balancing Act
Getting the most optimal data quality with the least effort is about balancing the use of internal and external data, where you can exploit interenterprise data sharing via interenterprise MDM through combining 2nd-party and 3rd-party data in the way that makes most sense for your organization.
Interenterprise MDM is an emerging discipline in the data management world and one of the topics you can find on the Resource List at this site.
This site is list of solutions for MDM and the disciplines adjacent to MDM. As always, it is good to have a definition of what we are talking about. So, here are some definitions of MDM and an Introduction to 9 adjacent disciplines:
MDM: Master Data Management can be defined as a comprehensive method of enabling an enterprise to link all of its critical data to a common point of reference. When properly done, MDM improves data quality, while streamlining data sharing across personnel and departments. In addition, MDM can facilitate computing in multiple system architectures, platforms and applications. You can find the source of this definition and 3 other – somewhat similar – definitions in the post 4 MDM Definitions: Which One is the Best?
The most addressed master data domains are parties encompassing customer, supplier and employee roles, things as products and assets as well as location.
PIM: Product Information Management is a discipline that overlaps MDM. In PIM you focus on product master data and a long tail of specific product information – often called attributes – that is needed for a given classification of products.
Furthermore, PIM deals with how products are related as for example accessories, replacements and spare parts as well as the cross-sell and up-sell opportunities there are between products.
PIM also handles how products have digital assets attached.
This data is used in omni-channel scenarios to ensure that the products you sell are presented with consistent, complete and accurate data. Learn more in the post Five Product Information Management Core Aspects.
DAM: Digital Asset Management is about handling extended features of digital assets often related to master data and especially product information. The digital assets can be photos of people and places, product images, line drawings, certificates, brochures, videos and much more.
Within DAM you are able to apply tags to digital assets, you can convert between the various file formats and you can keep track of the different format variants – like sizes – of a digital asset.
DQM: Data Quality Management is dealing with assessing and improving the quality of data in order to make your business more competitive. It is about making data fit for the intended (multiple) purpose(s) of use which most often is best to achieved by real-world alignment. It is about people, processes and technology. When it comes to technology there are different implementations as told in the post DQM Tools In and Around MDM Tools.
The most used technologies in data quality management are data profiling, that measures what the data stored looks like, and data matching, that links data records that do not have the same values, but describes the same real world entity.
RDM: Reference Data Management encompass those typically smaller lists of data records that are referenced by master data and transaction data. These lists do not change often. They tend to be externally defined but can also be internally defined within each organization.
Examples of reference data are hierarchies of location references as countries, states/provinces and postal codes, different industry code systems and how they map and the many product classification systems to choose from.
CDI: Customer Data Integration is considered as the predecessor to MDM, as the first MDMish solutions focused on federating customer master data handled in multiple applications across the IT landscape within an enterprise.
The most addressed sources with customer master data are CRM applications and ERP applications, however most enterprises have several of other applications where customer master data are captured.
CDP: Customer Data Platform is an emerging kind of solution that provides a centralized registry of all data related to parties regarded as (prospective) customers at an enterprise.
In that way CDP goes far beyond customer master data by encompassing traditional transaction data related to customers and the emerging big data sources too.
Right now, we see such solutions coming both from MDM solution vendors and CRM vendors as reported in the post CDP: Is that part of CRM or MDM?
ADM: Application Data Management is about not just master data, but all critical data that is somehow shared between personel and departments. In that sense MDM covers all master within an organization and ADM covers all (critical) data in a given application and the intersection is looking at master data in a given application.
ADM is an emerging term and we still do not have a well-defined market – if there ever will be one – as examined in the post Who are the ADM Solution Providers?
PXM: Product eXperience Management is another emerging term that describes a trend to positioning PIM solutions away from the MDM flavour and more towards digital experience / customer experience themes.
In PXM the focus is on personalization of product information, Search Engine Optimization and exploiting Artificial Intelligence (AI) in those quests.
PDS: Product Data Syndication connects MDM, PIM (and other) solutions at each trading partner with each other within business ecosystems. Product data syndication is often the first wave of encompassing interenterprise data sharing. You can get the details in the post What is Product Data Syndication (PDS)?