
One of the core capabilities around data quality in Master Data Management (MDM) solutions is providing data matching functionality with the aim of deduplicating records that describes the same real-world entity and thereby facilitate a 360 degree view of a master data entity.
Identifying the duplicates is one thing that is hard enough. However, how to resolve the result of the deduplication process is another challenge.
There are three main approaches for doing that:
Enlarge the image here.
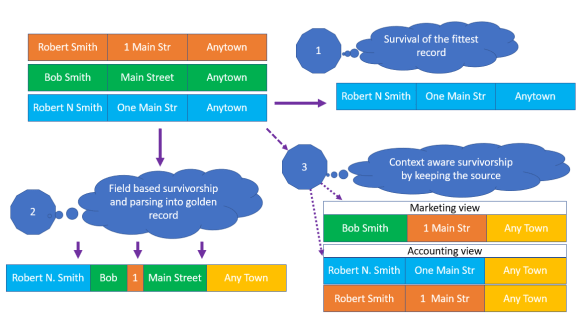
In the above example we have three records: An orange, a green and a blue one. They are considered to be duplicates, meaning they describe the same real-world person.
1: Survival of the fittest record
Selecting the record that according to a data quality rule is the most fit is the simplest approach. The rule(s) that determines which record that will survive is most often based on either:
- Lineage, where the source systems are prioritized
- Completeness, like for example which record has the most fields and characters filled
The downside of this approach is that surviving record only have data quality of that selected record, which might not be optimal, and that valuable information for deselected records might get lost.
Data quality tools that are good at identifying duplicates often has this simple method around survivorship.
In the above example the blue record wins and this record survives in the MDM hub, while the orange and the green record only survives in the source system(s).
2: Forming a golden record
In this approach the information from each data element (field) is selected from the record that, by given rules, is the best fit. These rules may be based on lineage, completeness, validity or other data quality dimensions.
Data elements may also be parsed, meaning that the element is split into discrete parts as for example an address line into house number and street name. The outcome may also be a union of the (parsed) data elements coming from the source systems.
In that way a new golden record is formed.
Additionally, values may also be corrected by using external directories which acts as a kind of source system.
This approach is more complex and while solving some of the data quality pain in the first approach, there will still be situations of mixing wrongly and lost information as well as it is hard to rollback an untrue result.
In the above example the golden record in the MDM hub is formed by data elements from the blue, green and orange record – and the city name is fetched from an external directory.
3: Context aware survivorship
In this approach the identified duplicates are not physically merged and purged.
Instead, you will by applying lineage, completeness and other data quality dimension based rules be able to make several different golden record views that are fit in a given context. The results may differ both around the surviving data elements and the surviving data records.
This is the most complex approach but also the approach that potentially has the best business fit. The downsides include, besides the complexity, possible performance issues not at least in batch processing.
In the above example the MDM hub includes the orange, green and blue record and presents one surviving golden record for marketing purposes and two surviving golden records for accounting purposes.

In my consulting days, this was the MOST difficult part of a project. It was easy enough to do, technically. However, what was hard was trying to get the different parts of the business to agree HOW to do it. Everyone wanted to do it. But everyone wanted to do it THEIR way. A lot of otherwise good MDM project went ‘bad’ on this issue.
LikeLike
Indeed Gino, this is a troublesome issue. I tend to favor the third option. However only a few solutions on the market – including Reltio – have this capability.
LikeLike
like the approach of Business best fit, but managing multiple golden records for a given customer master data record may be cumbersome to govern? After survivorship comes propagation. It may be more complex to manage if rules are complex.
LikeLike
Yes I have implemented Duplicate suspect Processing for many clients and its toughest part to merge and split the parties based on score;
LikeLike