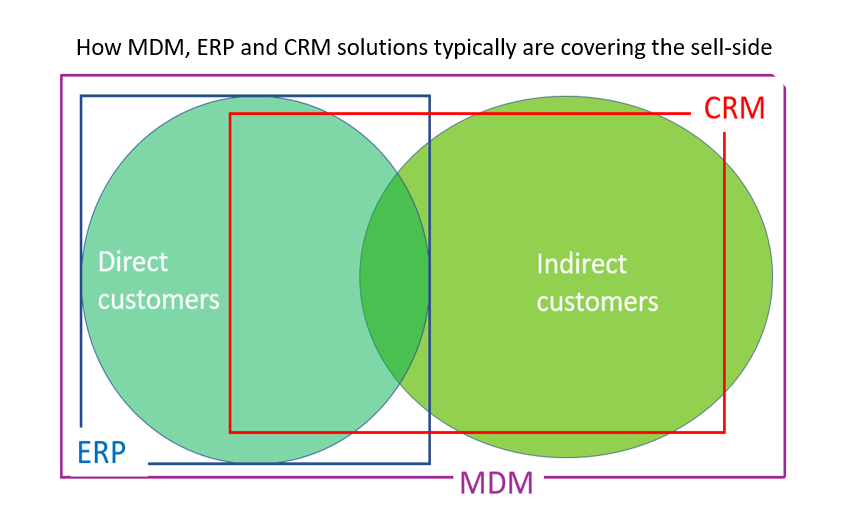
When working with Master Data Management (MDM) for the customer master data domain one of the core aspects to be aware of is the union, intersection and difference between direct customers and indirect customers.
Direct customers are basically those customers that your organization invoice.
Indirect customers are those customers that buy your organizations products and services from a reseller (or marketplace). In that case the reseller is a direct customer to your organization.
The stretch from your organization via a reseller organization to a consumer is referred to as Business-to-Business-to-Consumer (B2B2C). This topic is told about in the post B2B2C in Data Management. If the end user of the product or service is another organization the stretch is referred to as Business-to-Business-to-Business (B2B2B).
The short stretch from your organization to a consumer is referred to as Direct-to-Consumer (D2C).
It does happen, that someone is both a direct customer and an indirect customer either over time and/or over various business scenarios.
IT Systems Involved
If we look at the typical IT systems involved here direct customers are managed in an ERP system where the invoicing takes place as part of the order-to-cash (O2C) main business process. Products and services sold through resellers are part of an order-to-cash process where the reseller place an order to you when their stock is low and pays you according to the contract between them and you. In ERP lingo, someone who pays you has an account receivable.
Typically, you will also handle the relationship and engagement with a direct customer in a CRM system. However, there are often direct customers where the relationship is purely administrative with no one from the salesforce involved. Therefore, these kinds of customers are sometimes not in the CRM system. They are purely an account receivable.
More and more organizations want to have a relationship with and engage with the end customer. Therefore, these indirect customers are managed in the CRM system as well typically where the salesforce is involved and increasingly also where digital sales services are applied. However, most often there will be some indirect customers not encompassed by the CRM system.
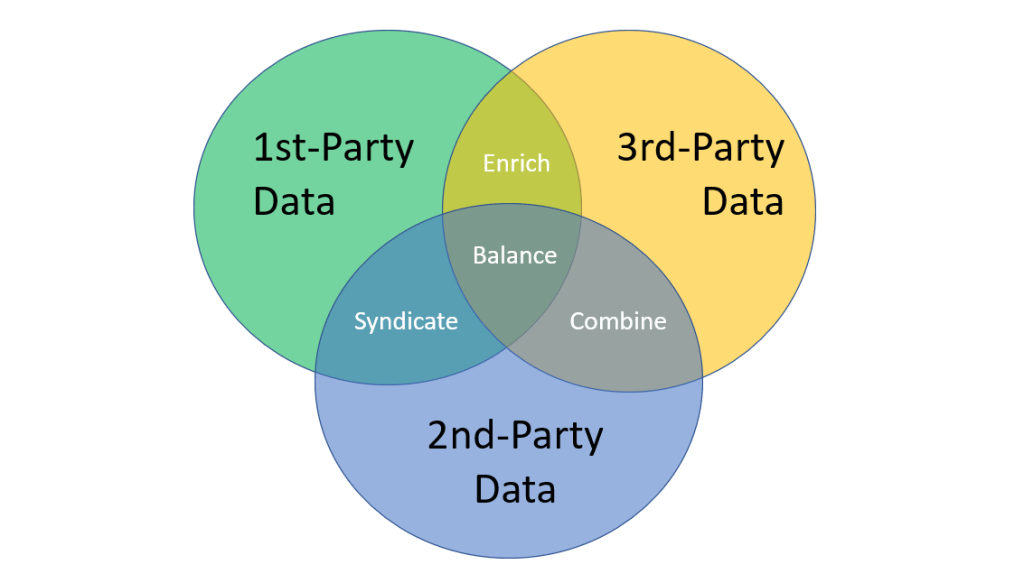
The Role of Master Data Management (MDM) in the context of customer master data is to be the single source for all customer data. So, MDM holds the union of customer master data from the ERP world and the CRM world.
An MDM platform also has the capability of encompassing other sources both internal ones and external ones. When utilized optimally, an MDM platform will be able to paint a picture of the entire sell-side space where your direct customers and indirect customers are.
Business Opportunities
Having this picture is of course only interesting if you can use it to obtain business value. Some of the opportunities are:
- More targeted product and service development by having more insight into the whole sell-side space leading to growth advancements
- Optimized orchestration of supply chain activities by having complete insight into the whole sell-side space and thereby fostering cost savings
- Improved ability to analyse the consequences of market change and changes in the economic environment in geographies and industries covered leading to better risk management.
This list has a presentation of some of the most innovative MDM and adjacent solutions for getting a combined view of your direct customers and indirect customers. Check out the list here.