Master Data Management (MDM) and the overlapping Product Information Management (PIM) discipline is the centre of which the end-to-end data supply chain revolves around in enterprises that produce and/or sell goods.

Nine essential master data processes are:
1: Onboard Customer Data
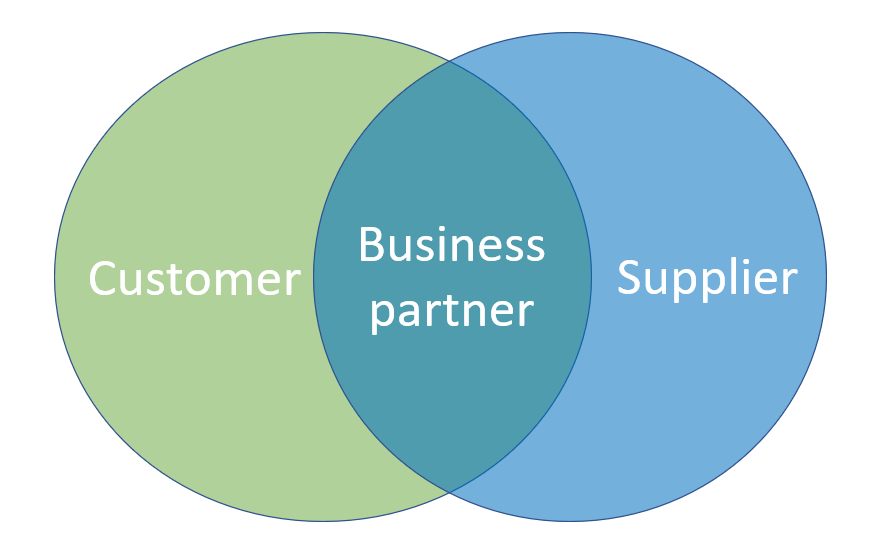
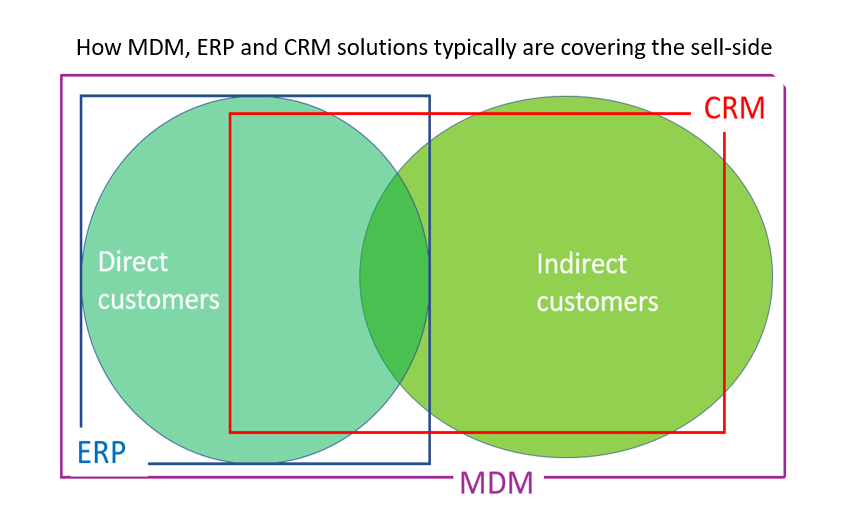
It starts and ends with the King: The Customer. Your organization will probably have several touchpoints where customer data is captured. MDM was born out of the Customer Data Integration (CDI) discipline and a main reason of being for MDM is still to be a place where all customer data is gathered as exemplified in the post Direct Customers vs Indirect Customers.
2: Onboard Vendor Data
Every organization has vendors/suppliers who delivers direct and indirect products as office supplies, Maintenance, Repair and Operation (MRO) parts, raw materials, packing materials, resell products and services as well. As told in a post on this blog, you have to Know Your Supplier.
3: Enrich Party Data
There are good options for not having to collect all data about your customers and vendors yourself, as there are 3rd party sources available for enriching these data preferable as close to capture as possible. This topic was examined in the post Third-Party Data and MDM.
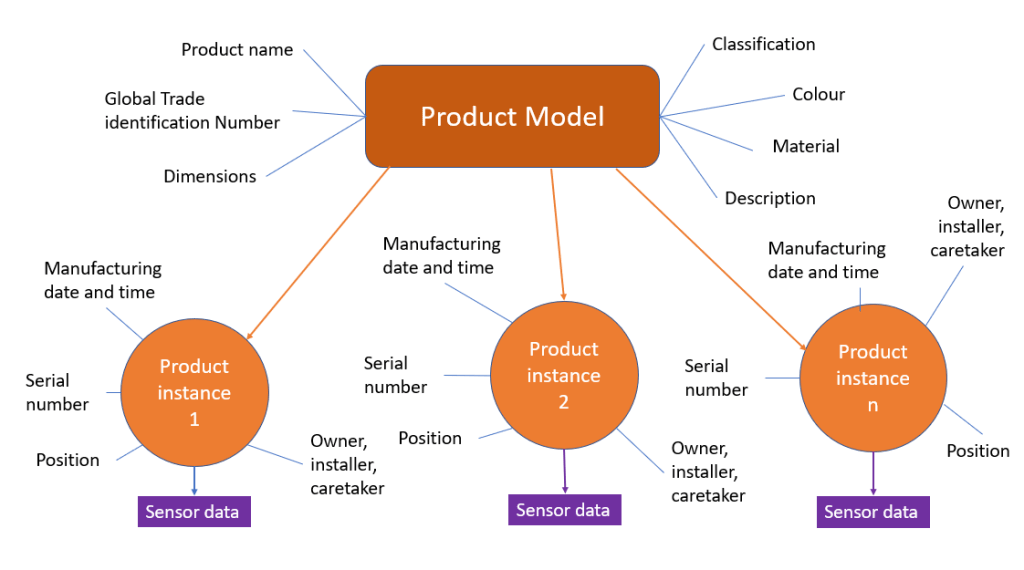
4: Onboard Product Data
While a small portion of product data for a small portion of product groups can be obtained via product data pools, the predominant way is to have product data coming in as second party data from each vendor/supplier. This process is elaborated in the post 4 Supplier Product Data Onboarding Scenarios.
5: Transform Product Data
As your organization probably do not use the same standard, taxonomy, and structure for product data as all your suppliers, you have to transform the data into your standard, taxonomy, and structure. You may do the onboarding and transformation in one go as pondered in the post The Role of Product Data Syndication in Interenterprise MDM.
6: Consolidate Product Data
If your organization produce products or you combine external and internal products and services in other ways you must consolidate the data describing your finished products and services.
7: Enrich Product Data
Besides the hard facts about the products and services you sell you must also apply competitive descriptions of the products and services that makes you stand out from the crowd and ensure that the customer will buy from you when looking for products and services for a given purpose of use.
8: Customize Product Data
Product data will optimally have to be tailored for a given geography, market and/or channel. This includes language and culture considerations and adhering to relevant regulations.
9: Personalize Product Data
Personalization is one step deeper than market and channel customization. Here you at point-of-sale seek to deliver the right Customer Experience (CX) by exercising Product eXperience Management (PXM). Here you combine customer data and product data. This quest was touched in the post What is Contextual MDM?